Libsyn Podcast : Talking Drupal #447
Today we are talking about Drupal Single Sign On, The Benefits it brings to the Drupal Community, and A new book called Fog & Fireflies with guest Tim Lehnen. We’ll also cover Drupal.org…

Today we are talking about Drupal Single Sign On, The Benefits it brings to the Drupal Community, and A new book called Fog & Fireflies with guest Tim Lehnen. We’ll also cover Drupal.org…

To build experience with Linux commands, there are a few things you can do. First, try to use the command line interface as much as possible. This will give you practice with the…

Legacy systems typically operate based on restricting and inflexible processes that are difficult to adapt to modern business needs. Conversely, ITIL principles place a strong emphasis on flexibility and adaptability. Consequently, organisations must…

he remarked. The session saw lively interactions that went beyond mere technical discussions, making it a vibrant platform for networking and community building.”Besides the technical talks, the event also served as a wonderful…

If you click the “Use VoiceOver” button you are well on your way to using VO to test your websites and apps. One thing to keep in mind is that VO is optimized…

A few tips with Composer Drupal will help you save time. Here they are: Composer 2: What is it? Composer looks for dependencies on its own. You must register repositories using the repositories…

Training data bias could also lead to a variety of security dangers, and for one good reason. Most of the AI databases, even the ones related to cybersecurity, can experience what we call…
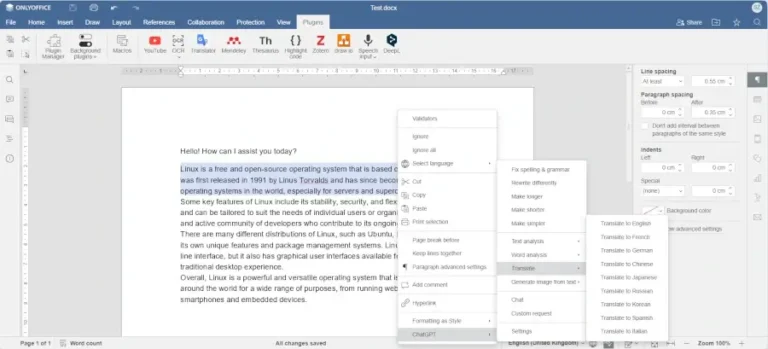
Smartcat supports more than 280 languages. It can also create glossaries and translation memories, which makes the translation process easier. The more you translate with Smartcat, the more accurate translations you get. ONLYOFFICE…

Hostinger offers a domain name checker to help you find the perfect domain for your store, with various top-level domains (TLDs) available to make your site address stand out. This approach not only…